OdinBench v0.1: Measuring False Positives in LLM Security Scanners
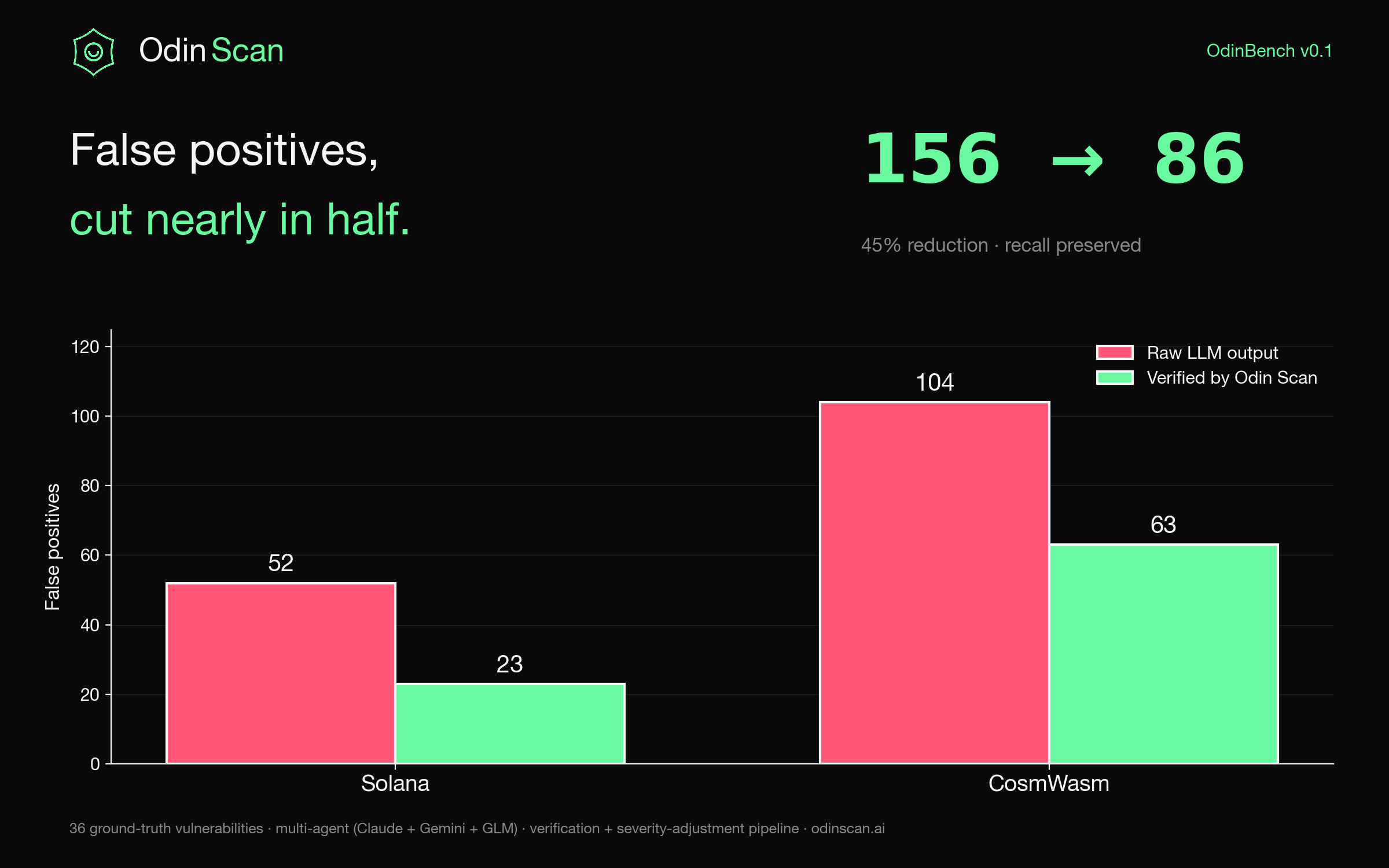
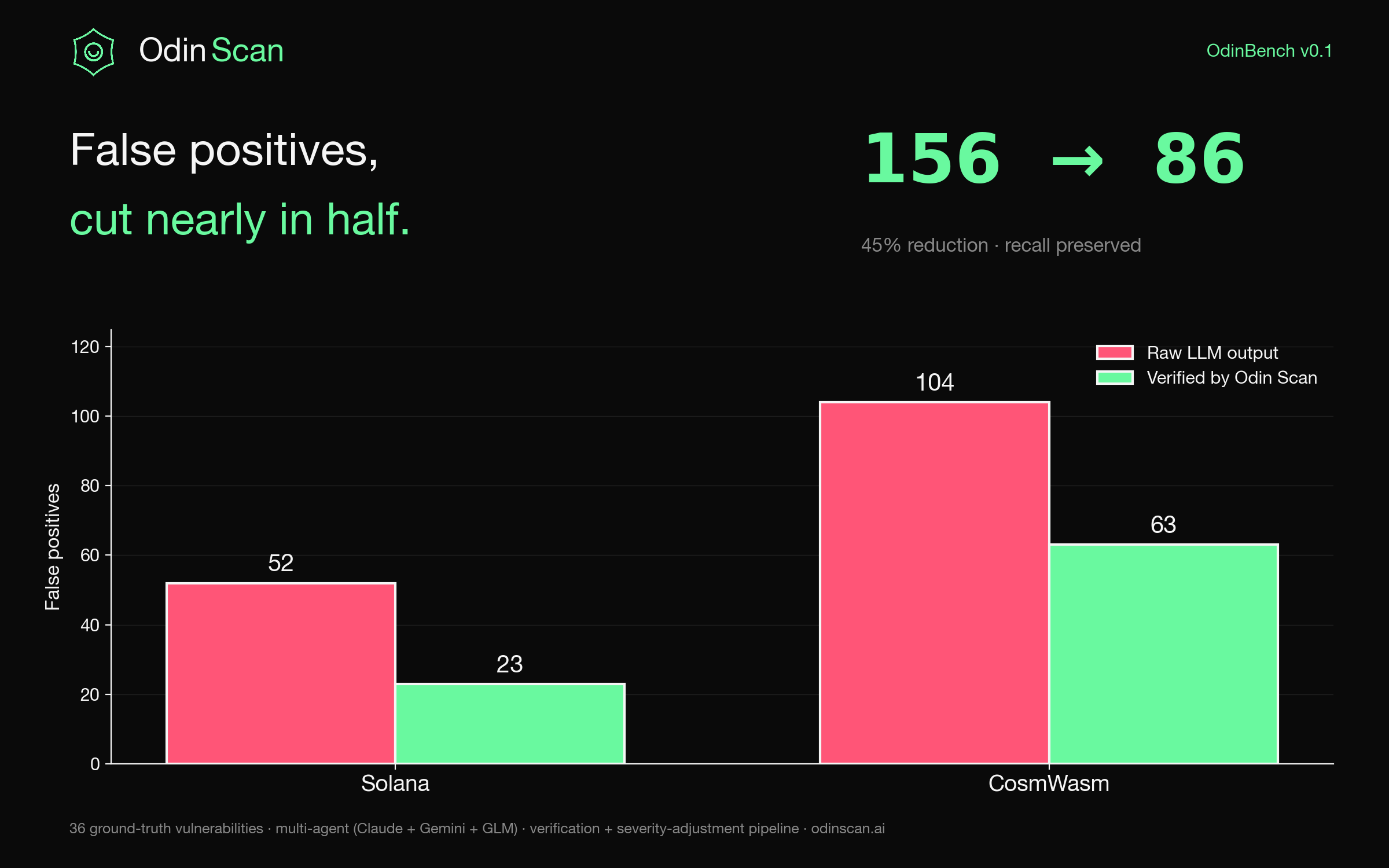
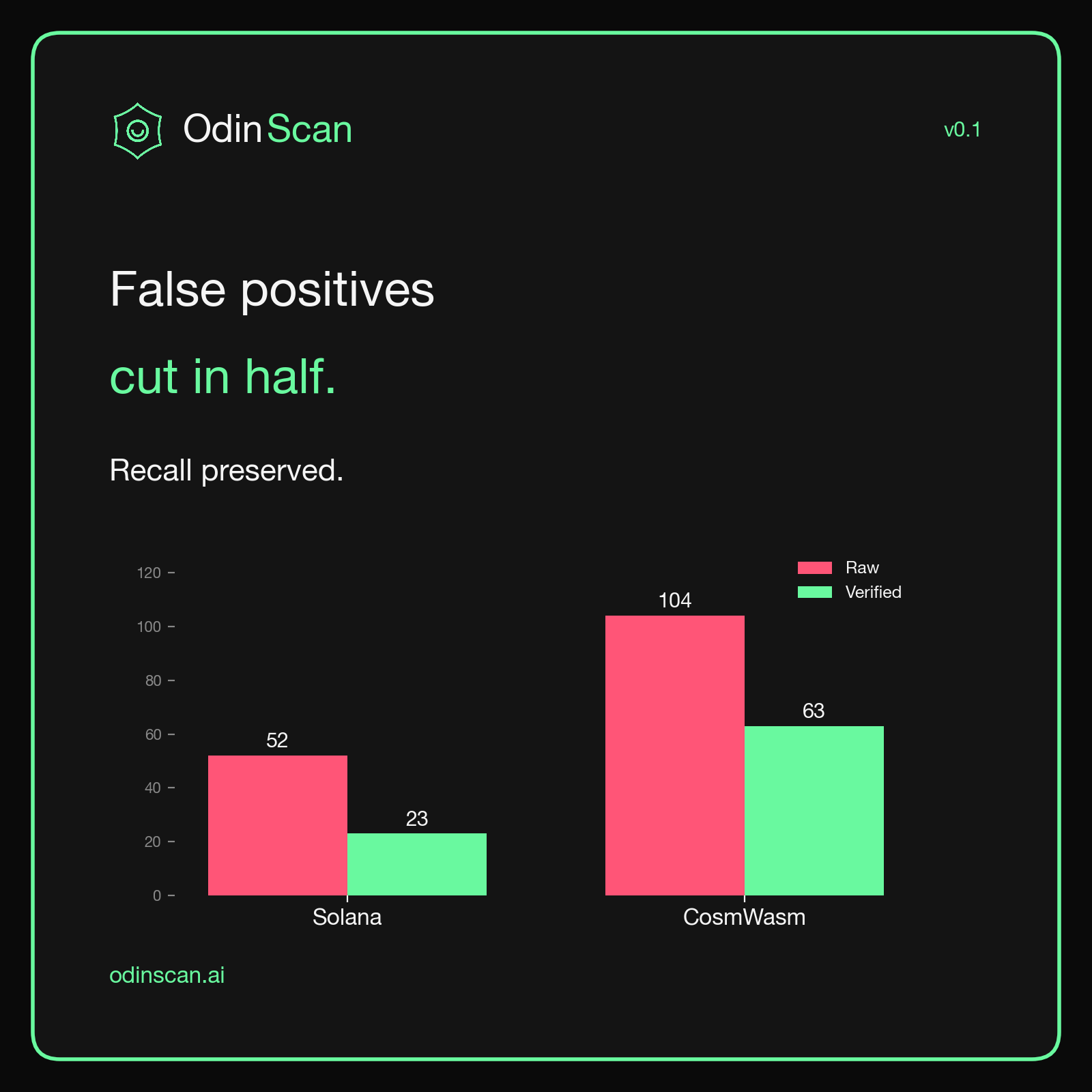
TL;DR. Most "AI security scanners" ship without measuring themselves. We didn't. On 38 smart contracts across Solana and CosmWasm, our verification pipeline cuts raw LLM false positives from 156 to 86, a 45% reduction, while losing only a handful of true positives. On EVM, every Critical-severity finding we surface is a real bug (100% precision, 80% recall on the Critical class).
This is OdinBench v0.1. The corpus, the configs, and the harness are open. You can re-run it.
Why we built this
If you have shipped any LLM-powered code analysis, you already know the dirty secret: out of the box, an LLM auditing a smart contract will flood you with findings. Most are wrong. Engineers stop reading after the third "potential reentrancy" on a view function.
The standard industry response is to either (a) hide the noise behind a paywall and call it "AI-curated", or (b) post a blog with cherry-picked positive examples. Neither tells you what the tool actually does on your code.
We took a different approach. We built three things in parallel:
- A multi-agent orchestrator that runs Claude, Gemini, and GLM concurrently and aggregates their findings.
- A verification + severity-adjustment pipeline that filters the aggregated findings using contextual heuristics, repository-trust signals, and a second-pass LLM verifier.
- A benchmark harness that runs the whole stack against a fixed corpus of contracts with hand-labeled ground truth.
OdinBench is the output of step 3.
The corpus
Three platforms. 38 contracts. 36 ground-truth vulnerabilities.
| Platform | Contracts | Ground-truth vulns | Source |
|---|---|---|---|
| EVM | 8 | 30 | Synthetic + known-exploited patterns |
| Solana | 10 | 18 | Synthetic Anchor + native programs |
| CosmWasm | 20 | 18 | Oak Security CTF + synthetic + clean |
All contracts and labels live in our benchmark corpus. The clean contracts (standard CosmWasm template, CW20 base) are deliberately included to measure hallucination rate on safe code.
The metric that matters: false positives
Recall is the easy half. Throw enough LLMs at a contract and you will find most of the real bugs. The hard part is not drowning the developer in noise.
Here is what the multi-agent stack produces before verification, and after:
- Solana: 52 raw false positives, 23 after verification. A 56% reduction.
- CosmWasm: 104 raw false positives, 63 after verification. A 39% reduction.
- Combined: 156 to 86. A 45% reduction.
The recall cost is real but small: we drop from 100% to 83% on Solana, and from 56% to 44% on CosmWasm. We are not pretending these numbers are perfect. They are honest, and they are headed in the right direction with every prompt and filter iteration.
Where the pipeline shines: Critical severity on EVM
Severity matters more than count. A scanner that buries one Critical bug in 200 Lows is useless. Here is the EVM Critical-class slice:
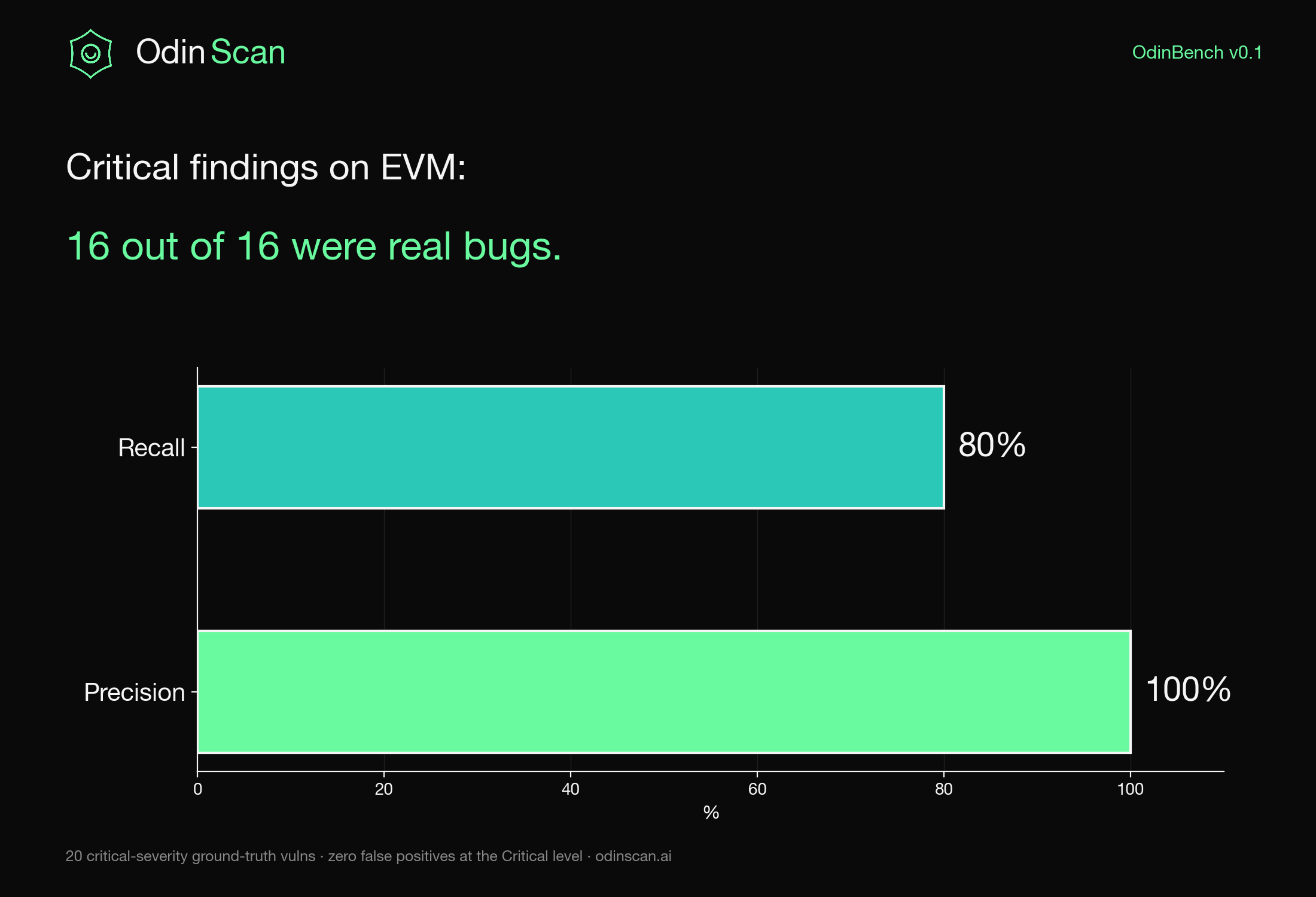
Precision: 100%. Recall: 80%.
When OdinBench labels a finding "Critical" on EVM, it has been right every single time across 16 true positives. It misses 4 out of 20 Critical vulns in the corpus, which is the part we are working on next. But the Critical class is where developer attention is most expensive, and that is where false positives hurt the most. Zero is the right number.
How the verification pipeline works
Three things, in order:
1. Pre-filter. Hand-written checks per platform that flag obvious LLM hallucinations: integer overflow claims on Solidity 0.8+, "missing reentrancy guard" on view functions, "unchecked external call" on calls inside a try/catch. The pre-filter is conservative: if it is not 99% sure the finding is wrong, it lets it through.
2. Repository trust model. We extract context from the repo: README, audit history, compiler version, interface usage. A finding flagged on a function that the README explicitly documents as "admin-only, trusted" gets demoted, not deleted. The trust model is configurable per scan via --trust-model admin-trusted|admin-untrusted.
3. Severity adjustment. A second-pass LLM verifier re-scores each remaining finding against the original code with explicit instructions to demote anything that is not exploitable in the repository's actual trust context. Demoted findings move to Informational instead of disappearing, so nothing is silently dropped.
The pipeline is the difference between 156 raw FPs and 86 verified ones. It is also the difference between an LLM scanner you can put in CI and one you cannot.
What is honest, and what is not yet
Honest. We measured ourselves on a fixed corpus. The numbers are not retouched. The filtered_overall block in every result file includes how many true positives we lost to filtering, because that is the cost.
Not yet. Three things we owe v0.2:
- A side-by-side comparison against Slither, Aderyn, and Mythril on the same corpus. Right now OdinBench measures OdinBench. The next version measures everyone.
- A larger, harder corpus. 38 contracts is a starting point. We want 200, with the top exploits of 2024 and 2025 represented.
- Better Critical-severity recall on CosmWasm. Catching 33% of Critical CosmWasm bugs is not good enough. We know which categories are weakest (FlashLoan, NumericalIssue) and we are writing detectors.
The headline, in one card
What this is for
OdinBench is not a marketing chart. It is the contract we are signing with users.
If you run Odin Scan on your repository and it fires more false positives than the bench predicts, that is a bug in the tool and we want to know. If you hit a Critical on our scanner and it turns out to be wrong, that is the kind of regression we built the harness to catch.
We will publish v0.2 within 60 days, with cross-tool comparisons and a larger corpus.
Try it
Ready to see what the verified pipeline catches on your code? Sign up for a free trial and run your first scan in under a minute. 7-day free trial. No credit card required.
Questions, feedback, or a corpus you want us to add to v0.2? Reach out at support@odinscan.ai.
Notes on methodology. All runs use the all-accuracy config: Claude Opus + Gemini Pro + GLM 4.7, accuracy mode, verification enabled. Ground-truth labels were established by manual review of each contract by two reviewers. The clean contracts are standard, unmodified library templates and are scored only on hallucination rate (any finding on a clean contract counts as a false positive).